exOS应用程序接口使用缓冲区来确保每个已发布数据集的传输,而总体目标是确保在每个周期内至少能发布一个数据集。在这里,exOS是为解决"典型"数据传输量而预先配置的,其重点是快速、同步的数据传输和进程执行。exOS系统确保数据的一致性和数据传输(每个发布的数据集都按照数据集发布的顺序接收),这可以通过系统中的一些缓冲区来解决。作为默认设置,这些缓冲区是为解决最典型的使用情况而预先配置的,而对于需要交换大量数据或动态数据的特殊情况,这些预设的限制可能会适用。
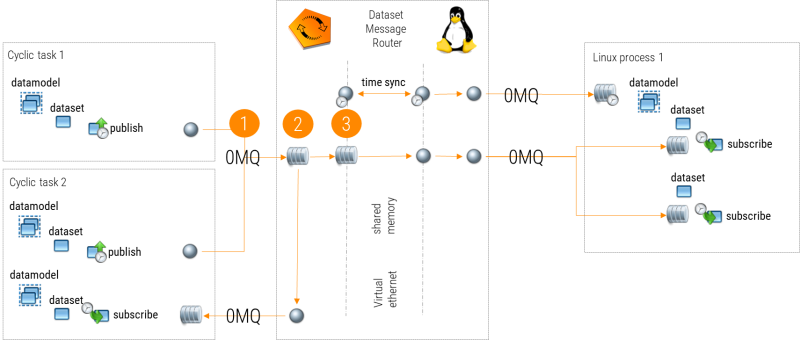
在AutomationRuntime中,应用程序(任务/库)与数据集消息路由器之间的ZMQ通信是通过线程安全的FIFO实现的,因为所有AR任务和库都使用单空间内存,因此不需要像Linux中那样的"真正"管道。这种机制比消息管道更快,但这种机制的FIFO缓冲区目前是预定义的。
▪zmq_fifo_size=250000
应用程序与数据集消息路由器(发送或接收方向)之间每个连接的数据都会预先分配到这一大小。在应用程序中使用大型数据集(100kB以上)时,建议不要在子结构中设置变量,否则包含缓冲区的结构在共享内存中占用的空间将与缓冲区本身相同。exOSAPI会对通过exos_dataset_publish()发送的所有数据集进行缓冲,因此250kB的数据限制也意味着,例如一个应用程序可以在一次突发(一次任务扫描)中发送20个大小为10kB的数据集。每次任务扫描(使用共享内存)结束时,ZMQ(FIFO)缓冲区中的数据集都会被收集到API发送缓冲区中,纯TCP连接则大约每25毫秒收集一次。
如果在FIFO已满时发布数据集,exos_dataset_publish()将返回EXOS_ERROR_SYSTEM_SOCKET_USAGE。
如果有特定应用需要更大的缓冲区,可以将FIFO的大小增加到~5MB(FIFO的最小值为50kB)。建议只有在真正需要时才更改此设置,因为在设置大小后,它会影响AR上的所有发送和接收消息缓冲区。
例如将所有应用程序的FIFO大小设置为400kB
include <zmq.h>
void _INIT ProgramInit(void)
{
zmq_ctx_set(NULL, ZMQ_FIFO_SIZE, 400000); //MAX: 5000000 MIN: 50000
}
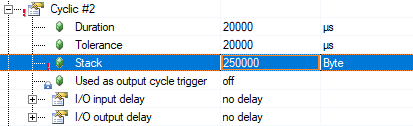
需要大FIFO缓冲区的另一个原因可能是需要发送大数据集。在这种情况下,自动化运行时任务类的堆栈大小需要增加到(至少)可用的最大数据集的大小。最大数据集大小为200kB,这意味着这种情况下需要250kB的堆栈大小。
如AR_ZMQ中所述,应用程序之间发送的所有数据集都会被缓冲,以便在系统无法发送特定数据集时通知用户。除zmq缓冲区外,每个数据集都有自己的缓冲区,用于在AR和Linux之间传输数据。该缓冲区的预定义值为
▪exos_lxi_send_buffer_items = 50
使用该发送缓冲区的原因是,通过共享内存或TCP/IP传输数据(在仿真中)可能比应用程序与数据集消息路由器之间的传输慢,尤其是同时发送多个数据集时。50个数据集的限制基本上意味着数据集可能会以突发方式(即紧密循环)发布,最大值为50个。现在,根据数据大小和传输类型(共享内存或TCP/IP),向远程系统实际传输数据所需的周期或多或少。因此,每个周期可能无法发布50个数据集(更多信息请参阅下一主题:传输缓冲区)。在这种情况下,以及在需要循环发布更多数据集的每种情况下,数据模型都应声明一个数据集数组并发布整个数组,而不是逐个发送每个数据集。
为了区分数据集何时被推送到API发送缓冲区,何时被传送到远程系统(通过共享内存或TCP/IP),exOSAPI提供了两种数据集事件:
▪EXOS_DATASET_EVENT_PUBLISHED - 数据集已被转发到 API 发送缓冲区
▪EXOS_DATASET_EVENT_DELIVERED - 数据集已通过 TCP/IP 或共享内存传送到远程系统。
如果传输层(TCP/IP或共享内存)无法在缓冲区填满之前传输所需的数据集发布请求,则传输端的数据集将收到EXOS_DATASET_EVENT_CONNECTION_CHANGED,其中dataset.connection_state=EXOS_STATE_ABORTED,且error=EXOS_ERROR_CODE_BUFFER_OVERFLOW错误。
在共享内存连接中,一旦数据传输到API发送缓冲区,所有数据集都会被单独处理,与每个数据模型的数据集数量无关。这意味着发布1个数据集和发布20个不同数据集的限制是一样的。此外,在内存方面也没有限制(只要分配的共享内存区域足够大),这意味着发布10字节数据和发布10k字节数据的限制相同。
数据集消息路由器会在每个DMR周期从所有连接的数据集读取API发送缓冲区。使用共享内存时,该周期与任务类系统同步,任务类可在exOS目标配置中配置。向远程系统发送数据时,每个数据集都会使用一个大小为
▪exos_lxi_shm_write_items = 10
由于环形缓冲区的读写是通过Hypervisor中的同步信号进行的,这意味着每个周期最多可传输10个数据集,而不会填满上一个API发送缓冲区。这方面的唯一瓶颈可能是ARZMQ缓冲区,默认情况下它会将每个周期的数据集传输限制为10x25kB。
模拟使用TCP/IP传输,每个数据模型连接通过一个套接字连接进行。这意味着需要考虑每个数据模型发布数据集的数量。换句话说,发送一个数据集和发送20个数据集(如果这些数据集属于同一个数据模型)的限制是不一样的。此外,由于传输是通过TCP/IP协议进行的,因此传输10kByte数据比传输10Byte数据所需的时间更长。
在这里,数据集消息路由器与AR任务周期异步运行,每个周期都会读取所有连接数据集的API发送缓冲区。由于通过TCP/IP传输数据无法在一次扫描内完成(TCP/IP采用握手方式),因此如果在一个周期内有多个数据集发布,则会分配一个额外的缓冲区来分块发送数据集变化。这对传输较小的数据集(最多1kB)有很大好处,因为这些数据集可以放入单个IP数据包的有效载荷中,但对发送大于TCP/IP有效载荷大小的数据集影响不大。可"分块"传输的数据集数量限制为
▪exos_lxi_eth_send_items = 20
这意味着,在良好的情况下,如果在一次扫描中发布了10个数据集,而传输只占用了2个数据集消息路由器周期,并且没有发送任何其他内容,那么就有可能继续以循环的方式这样做,每个周期发布10个数据集,因为在等待传输完成的过程中,API发送缓冲区将包含后面的10个数据集。换句话说,在这种"好"的情况下,每第二个数据集消息路由器周期将传输20个数据集。
如前所述,每个周期在TCP/IP连接中发布10个数据集而不填满API发送缓冲区是一种"非常好"的情况,因为很可能还有其他数据集或数据模型事件(连接/运行)需要通过同一套接字连接传送。因此,一个数据模型的所有发送请求都有一个等待队列,其大小为
▪exos_lxi_send_queue_size = 300
这意味着,每个套接字/数据模型连接可排队等待300个发送请求(每个请求都有一个API发送缓冲区)。这基本上意味着该队列可能不会被填满,因为每个数据模型有256个数据集的限制。基本上,这意味着在256个数据集中,每个周期只能有一个数据集发布其更改,而且即使数据集消息路由器负责请求排队,当TCP/IP连接在短时间内发生大量更改时,也会出现延迟,除非出现突发情况,否则在此连接上每个周期发布数据集的自然限制是,在API发送缓冲区被填满之前,大概只能发布10-20个数据集。
在向远程系统传送数据时,可能会希望"尽可能快地"发布数据,这样至少能在另一端接收到最新值(如温度)。但是,数据集的每一次变化并不都需要传输。在这种情况下,可以使用EXOS_DATASET_EVENT_DELIVERED事件来触发新值的发布。使用该事件可确保API发送缓冲区永远不会被一个特定的数据集填满,因为--当许多数据集同时发送时,EXOS_DATASET_EVENT_DELIVERED会在仿真(TCP/IP)连接上排队的数据集之后出现。 EXOS_DATASET_EVENT_DELIVERED将更深入地介绍这一主题。
The exOS API uses buffers to ensure the transmission of each published dataset, while the general aim is to ensure that at least one dataset can be published in each cycle. Here exOS is preconfigured to solve a "typical" amount of data transfer, which focuses on fast and synchronized data transmission and process execution. The exOS system ensures data consistency and data transfer (every published dataset is received in the same order that the datasets were published), which is solved by a number of buffers in the system. As a default, these buffers are preconfigured to solve the most typical use-cases, and for special cases where a lot - or dynamic - data needs to be exchanged, these preset limitations might apply.
In Automation Runtime, the ZMQ communication between the applications (tasks/libraries) and the Dataset Message Router is implemented via thread-safe FIFOs, as all AR tasks and libraries are using a single-space memory and therefore no "real" pipes are needed as in Linux. This mechanism is faster than message pipes, however the FIFO buffers for this mechanism are currently pre-defined.
•ZMQ_FIFO_SIZE=250000
the data of every connection between an application and the Dataset Message Router (in send or receive direction) is pre-allocated to this size. When using large datasets in the application (100kB+), it is advised not to have the variable in a sub structure, as otherwise the structure containing the buffer would take up the same amount of space in the shared memory as the buffer itself. The exOS API buffers all datasets sent via exos_dataset_publish() and so the 250kB data limitation also means that for example 20 datasets with the size of 10kB can be sent in one burst (within one task scan) for one application. The datasets in the ZMQ (FIFO) buffer is collected in the API send buffer at the end of every task scan (using shared memory) and approximately every 25ms for pure TCP connections.
If a dataset is published when the FIFO is full, exos_dataset_publish() will return with EXOS_ERROR_SYSTEM_SOCKET_USAGE.
Should there be specific applications requiring larger buffers, the size of the FIFO can be increased up to ~5MB (smallest possible value for the FIFO is 50kB). It is advised only to change this setting when really needed, as it affects all send and receive message buffers on AR after the point of setting the size.
Example: Set the FIFO size to 400kB for all applications
include <zmq.h>
void _INIT ProgramInit(void)
{
zmq_ctx_set(NULL, ZMQ_FIFO_SIZE, 400000); //MAX: 5000000 MIN: 50000
}
Another thing to point out when requiring large FIFO buffers, is that it probably comes from the need of sending large datasets. Here the stack size of the Automation Runtime Taskclass needs to increased to the size of (at least) the largest dataset available. The maximum dataset size is 200kB, meaning 250kB stack size is necessary for such a use-case.
As mentioned in AR_ZMQ, all datasets sent between applications are buffered so that the user will be notified in case the system was not able to send a certain dataset. Additional to the zmq buffer, each dataset has a buffer on its own for transferring data between AR and Linux. This buffer has a predefined value of:
•EXOS_LXI_SEND_BUFFER_ITEMS = 50
The usage for this send buffer is that the transmission of data via shared memory or TCP/IP (in simulation) can be slower than the transmission between the application and the Dataset Message Router, especially when more than one dataset is sent at a time. The limitation of 50 basically means that datasets may be published in bursts (i.e in a tight loop) with the maximum of 50 values. Now, depending on the data size and the transmission type (shared memory or TCP/IP), more or less cycles are needed to actually transfer the data to the remote system. It may therefore not be possible to publish for example 50 datasets every cycle (see more in the following topic: Transmission Buffers). In that case, and in every case where more datasets should be published cyclically, the datamodel should instead declare an array of that dataset and publish the whole array rather than sending each dataset one-by-one.
To distinguish between a dataset has been pushed to the API send buffer from when it has been delivered to the remote system (via shared memory or TCP/IP), exOS API offers two dataset events:
•EXOS_DATASET_EVENT_PUBLISHED - dataset has been forwarded to the API send buffer
•EXOS_DATASET_EVENT_DELIVERED - dataset has been delivered to the remote system via TCP/IP or shared memory
Should the transport layer (TCP/IP or shared memory) not be able to transfer the required dataset publish requests before filling the buffer, the dataset on the transmitting end recieves an EXOS_DATASET_EVENT_CONNECTION_CHANGED with dataset.connection_state = EXOS_STATE_ABORTED, and error=EXOS_ERROR_CODE_BUFFER_OVERFLOW.
In a shared memory connection, as soon as data has been transferred to the API send buffer, all datasets are treated individually, independent of the number of datasets per datamodel. This means the same limit is applied to publishing 1 dataset as to publishing for example 20 different datasets. Furthermore, there is no limitation in terms of memory (as long as the allocated shared memory area is large enough), meaning the same limits apply when publishing 10Byte data as when publishing 10kByte data.
The Dataset Message Router reads the API Send Buffer from all connected datasets every DMR cycle. When using shared memory, this cycle is synchronized with the taskclass system, and the taskclass can be configured in the exOS Target configuration. When sending data to the remote system, each dataset uses a ringbuffer for transferring with the size of
•EXOS_LXI_SHM_WRITE_ITEMS = 10
As the reading and writing of this ringbuffer takes place via synchronized signals in the Hypervisor, it means that up to 10 datasets can be transferred every cycle without filling up the previous API send buffer. The only bottleneck in this regard can be the AR ZMQ BUFFER that would as a default limit the transmission to 10x25kB datasets each cycle.
Simluation is using TCP/IP transmission, where each datamodel connection takes place via one socket connection. This means that the number of published datasets per datamodel needs to be accounted for. In other words, the same limits do not apply when sending one dataset as when sending 20 datasets, if those belong to the same datamodel. Furthermore, as transmission takes place via the TCP/IP protocol, it takes longer to transmit 10kByte data than to transmit 10Bytes data.
Here, the Dataset Message Router runs asynchronously to the AR taskcycle, where the API Send Buffer from all connected datasets are read every cycle. As transmission of data via TCP/IP cannot be accomplished within one scan (TCP/IP uses handshake), an additional buffer is allocated to send dataset changes in chunks, should there be more than one dataset published within a cycle. This has great benefits when transferring smaller datasets (up to 1kB) - as these can go into the payload of a single IP packet, but not a very big effect when sending datasets bigger than the TCP/IP payload size. The number of datasets that can be "chunked together" into one transmission is limited to
•EXOS_LXI_ETH_SEND_ITEMS = 20
Which means that in a good scenario, if 10 datasets are published within one scan, and transmission only occupies 2 Dataset Message Router cycles, and nothing else is sent, then it is possible to continue doing this in a cyclic manner, publishing 10 datasets per cycle, as the API Send Buffer will contain the 10 following datasets while waiting for the transmission to complete. In other words, in this "good" scenario, 20 datasets would be transferred in chunks every second Dataset Message Router cycle.
As indicated, publishing 10 datasets per cycle in a TCP/IP connection without filling up the API send buffer is an "extremely good" scenario, as there are most likely also other datasets or datamodel events (connected / operational) that need to come across via the same socket connection. For this reason, there is a waiting queue for all send requests of one datamodel, that has the size of
•EXOS_LXI_SEND_QUEUE_SIZE = 300
This means, that 300 requests for sending (each one with an API Send Buffer) can be queued for each socket / datamodel connection. This basically means that this queue is likely not to be filled, as there is the limitation of 256 datasets per datamodel. Basically it means that of the 256 datasets, only one dataset can publish its changes per cycle, and even though the Dataset Message Router takes care of queuing requests, there will be delays when many changes happen within a short period of time on a TCP/IP connection, and unless this represents a burst situation, publishing datasets every cycle on this connection has a natural limit of probably 10-20 datasets before the API Send Buffer is filled.
When delivering data to the remote system, there might be the desire to publish data "as fast as possible", so that at least the latest value (like a temperature) is received on the other end. However, it is not required that every change of the dataset is transferred. In this case, the EXOS_DATASET_EVENT_DELIVERED event can be used to trigger the publishing of a new value. Using this event will ensure that the API send buffer is never filled for one perticular dataset, in that - when many datasets are sent simultaneously, the EXOS_DATASET_EVENT_DELIVERED will come later for the datasets that got queued on Simulation (TCP/IP) connections. The exos_dataset_event_cb goes in more depth regarding this topic.